One-way, fire & forget
Semuanya berawal dari one way, fire & forget message. Dimana si pengirim message tidak memperdulikan kembalian atau response dari message tersebut. Contohnya adalah mengirimkan email ke alamat tertentu dan kita tidak menunggu lagi untuk kembalian nya. Karena kembalian atau response akan dikirimkan juga secara asynchronous pada waktu yang kita tidak tentukan.
Semua messaging pattern akan dibangun di atas one way fire and forget. Beberapa pattern yang ada adalah Return Address Pattern, Correlated Request/Response, dan Publish/Subscribe.
Mekanisme nya adalah client akan mengirimkan message dan langsung melanjutkan aktifitas yang lain tanpa menunggu. Setiap message memiliki ID. Message ID dapat digunakan dalam proses deduplication di penerima. Hal ini memudahkan queueing sistem untuk melakukan retry pada saat network buruk.
MSMQ memiliki mekanisme yang unik.
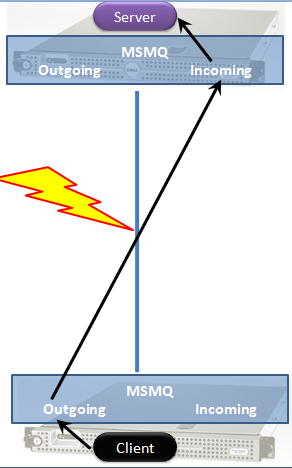
MSQM memungkinkan pengiriman pesan secara store and forward. Ketika client mengirimkan message, maka message tersebut akan dikirimkan ke outgoing queue yang ada di local client tersebut. Model komunikasinya adalah syncrhonous dan blocking. Salah satu kemungkinan gagal hanyalah jika outgoing queue penuh. Hal ini dapat terjadi jika mesin tujuan dari message tersebut offline pada satu masa dan client tetap mengirimkan banyak message. Pada satu masa maka queue tersebut akan penuh.
Store and forward disini jelas sekali maksudnya adalah infrastructure queue menyimpan message tersebut di local terlebih dahulu dan kemudian melakukan forward message tersebut ke tujuan nya di mesin lain di network.
Dari gambar di atas maka kita dapat melihat bahwa dari client ke outgoing queue merupakan pemanggilan local ( local invocation ) dari 2 proses yang berbeda. Sementara dari outgoing queue ke incoming queue yang ada di remote melalui network. Kemudian Server mengambil message tersebut dari incoming queue yang ada di lokal sistem dengan synch dan blocking.
Jika server crash pada saat message tiba di queue maka message tersebut akan tetap ada di queue dan tidak hilang. Ketika server hidup kembali maka message akan dapat di proses dari incoming queue. Message yang telah sampai di queue sifatnya persistent.

Mengenai masalah performance kita akan melihat pada microbenchmark performance dari RPC pada load yang kecil akan terlihat lebih cepat dibandingkan messaging. RPC akan memiliki low latency dibandingkan dengan messaging store and forward. Dengan store and forward kita akan memiliki 3 hop sampai message tersebut dapat di proses. Sedangkan RPC akan membuka koneksi langsung dari client process ke server process.
Mari kita membahas mengenai apa yang terjadi terhadap througput pada RPC. Salah satunya jika microservice anda menggunakan REST API blocking call maka hal ini yang akan terjadi juga pada system anda. Kita analisa dari thread dan memory yang di konsumsi program anda pada saat melakukan RPC synch blocking reqtinggi,uest ke server. Garbage collection akan menjaga memory tersebut sampai response kembali.Hal ini karena kita akan melakukan sesuatu terhadap response dari memory yang sebelumnya sudah kita alokasikan. Kita sudah tahu bahwa latency yang disebabkan oleh remote call tersebut mungkin saja cukup lama.
Garbage collection ( GC ) memiliki beberapa phase dalam membersihkan object yang dialokasikan di memory. Pertama kali GC akan mencari apakah kita sudah selesai dengan method tersebut atau tidak. Pada generation 0 ini semua berlangsung cukup cepat. Tentu saja belum karena kita masih menunggu response kembali dari remote call. Dan memory ini di tandai sebagai generation 1 sehingga tidak diganggu lagi untuk proses GC. Jika pada saat GC datang untuk melakukan pengecekan memory tersebut masih belum di release maka akan di promosikan menjadi generation 2.
Ketika memory tersebut masuk ke generation 2, maka GC tidak lagi aktif melakukan pengecekan terhadap memory tersebut. Sehingga kita akan memiliki memory leak pada kasus ini jika kita melakukan remote call yang membutuhkan waktu lama untuk selesai. Memory akan berkumpul di generation 2 sampai system tersebut memiliki load yang cukup tinggi. Ketika kita membutuhkan memory kita tidak menemukan lagi ruang yang tersisa. Barulah GC mencoba mengecek Gen 2 memory. Dan hal ini dilakukan dengan melakukan proses pause pada thread yang ada. Sehingga client akan membutuhkan waktu yang lebih lama karena proses pause tersebut.
Anda mungkin sudah dapat menduga bahwa akan ada efek domino dari sini. Client tek ntu saja akan mengalami masalah yang sama dengan generation 2 nya. Jadi semakin dalam microservice call anda terjadi semakin banyak memory preassure yang terjadi dan kemudian anda akan kehabisan memory. Jika hal ini hanya interaksi antara single server dan single client maka mungkin tidak merupakan masalah besar. Tetapi jika interaksi microservice anda sangat banyak pendekatan ini akan sangat berbahaya.
Jika client berusaha melakukan call terhadap remote method dan server tidak dapat lagi mengalokasikan thread dan kehabisan memory, maka koneksi tersebut akan di reject oleh server. Salah satu contoh exception nya adalah ConnectionRefusedByRemoteHost. Mekanisme ini lah yang dilakukan oleh RPC jika kehabisan thread atau memory. Hal ini juga berlaku terhadap lock di database. Web server juga akan menyadari bahwa proses tersebut dalam posisi berbahaya dan akan melakukan recycle terhadap proses tersebut.
Dengan messaging hal ini sangat berbeda sekali, di messaging system akan ada queue dimana queue adalah tempat penyimpanan atau persistent storage dimana message tersebut akan diletakkan. Meskipun server sibuk mengolah message-message yang lain. Hal inilah yang menyebabkan solusi dengan menggunakan queue lebih resilient pada load yang besar. Ketimbang menggunakan memory dan thread untuk menunggu response dari server, solusi queue menggunakan disk.
Banyak message bisa diam di outgoing queue di client dan incoming queue di server meskipun system ada di kapasitas dari peak. Jadi tidak ada koneksi client yang di reject. Karena tidak ada thread yang menunggu dan menimbun banyak memory di server dan client. Dan message based microservices akan running parallel dengan satu sama lain. Sehingga throughput menjadi semakin besar.
Tentu saja ada kemungkinan bahwa database down di queueing solution, sehingga outgoing queue di client dan incoming queue di server penuh. Tetapi selama database dapat dengan cepat hidup kembali maka kita tidak akan mengalami masalah. Jika kita menggunakan mekanisme HTTP maka kita harus melakukan retry dan mekanisme fault tolerance yang lain. Dan kemungkinan ada duplikasi message yang di kirimkan .